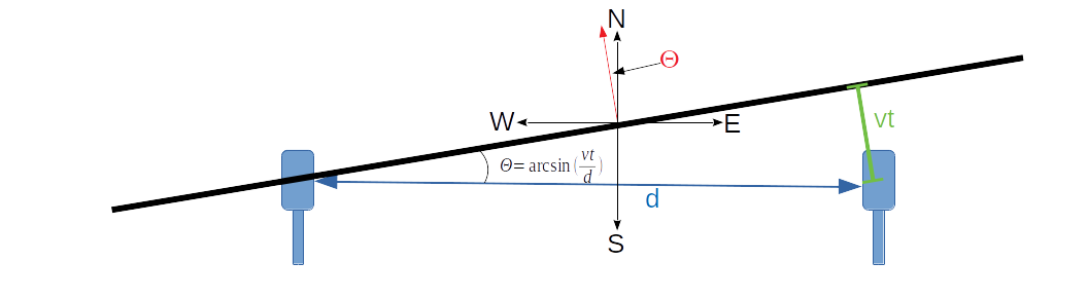
I’m starting to tackle the problem of identifying the individual sounds and correlating them with things detected by all the microphones. In order to do this I’m going to come up with abstractions for the data at each stage in the process. I’m going to start designing this from the bottom up. The terms for each abstraction are presented in bold the first time it is used.
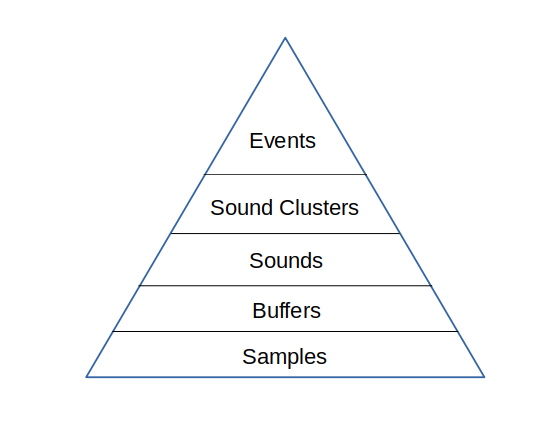
At the base of the pyramid of abstractions are samples. These are individual measurements of the voltage the microphone element produces. The samples are grouped together into buffers. Currently the size of a buffer is 512 samples, collected at approximately 20kHz. The microcontroller decides if the buffer is interesting by looking for samples where the voltage falls above a threshold. If interesting, it then forwards that buffer and preceding and following buffers to the server.
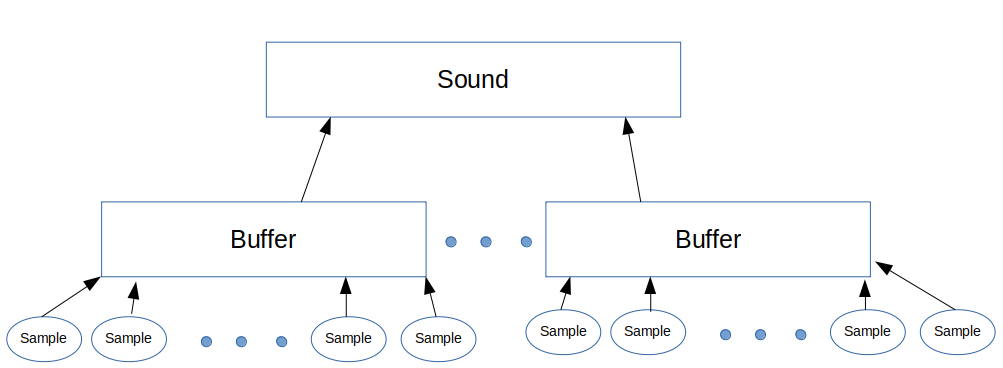
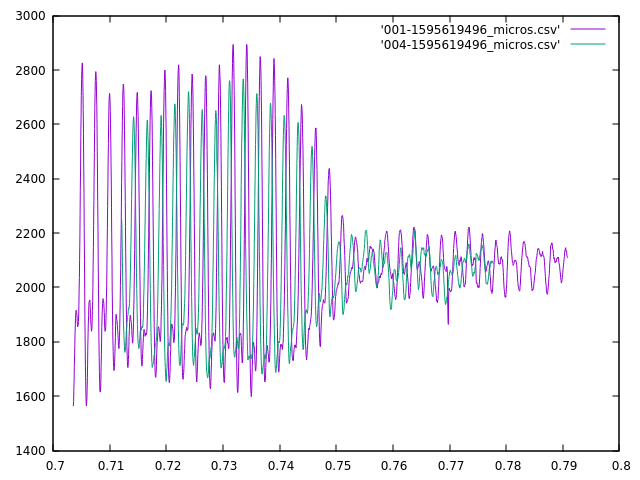
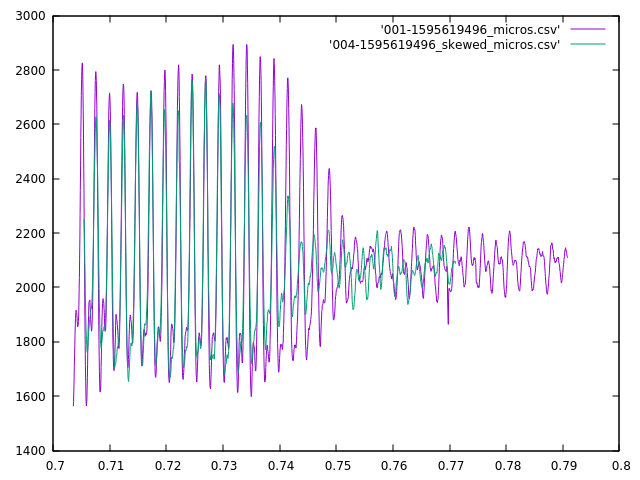
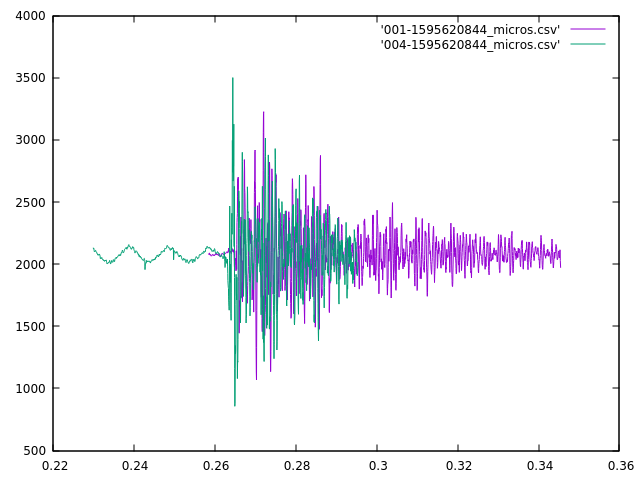
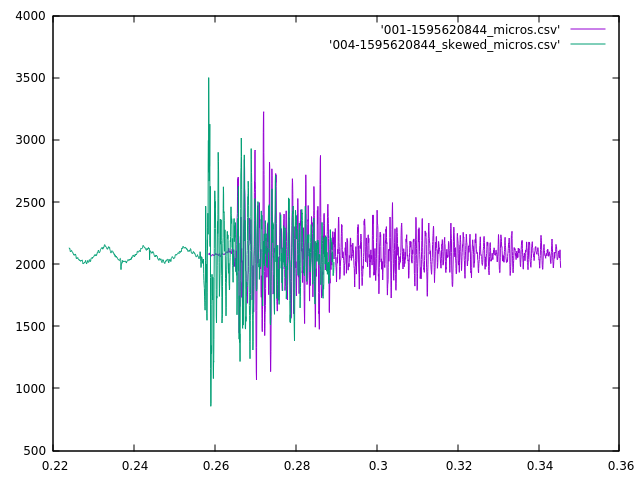
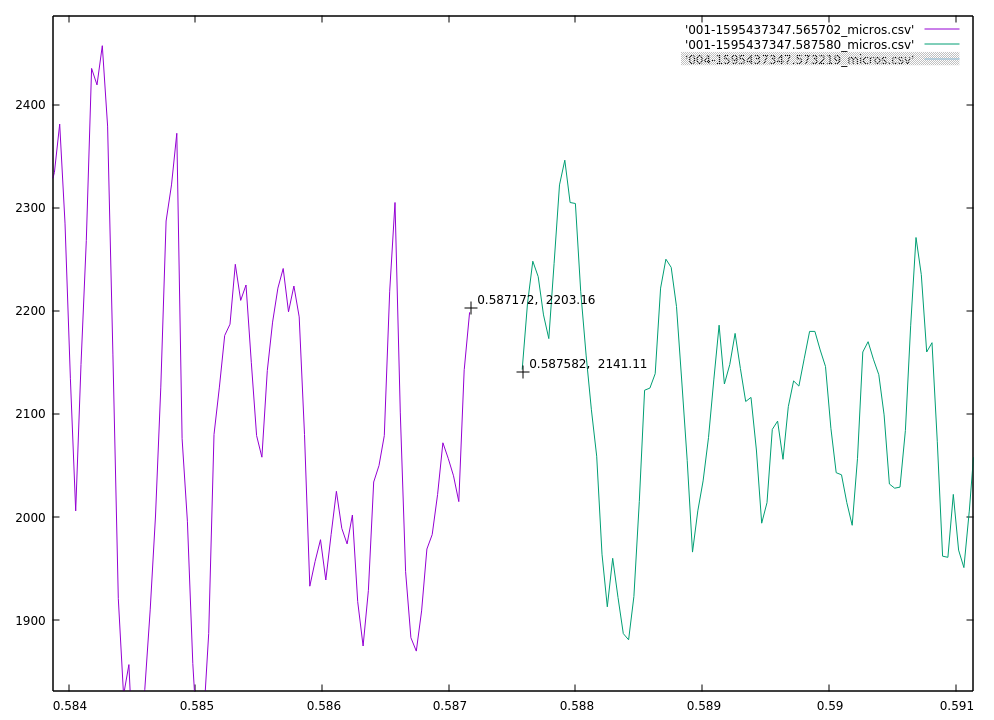
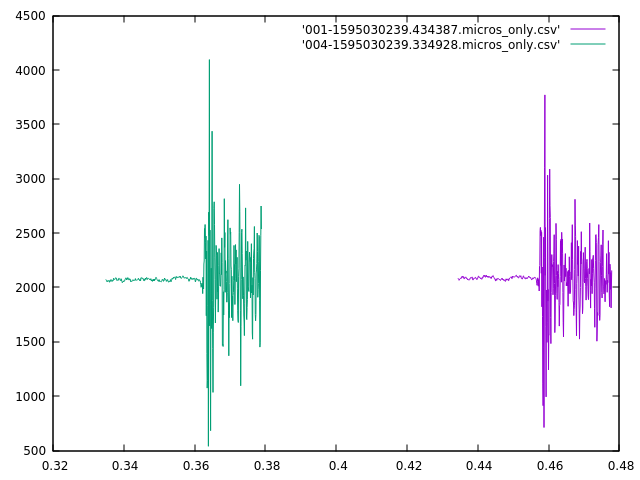
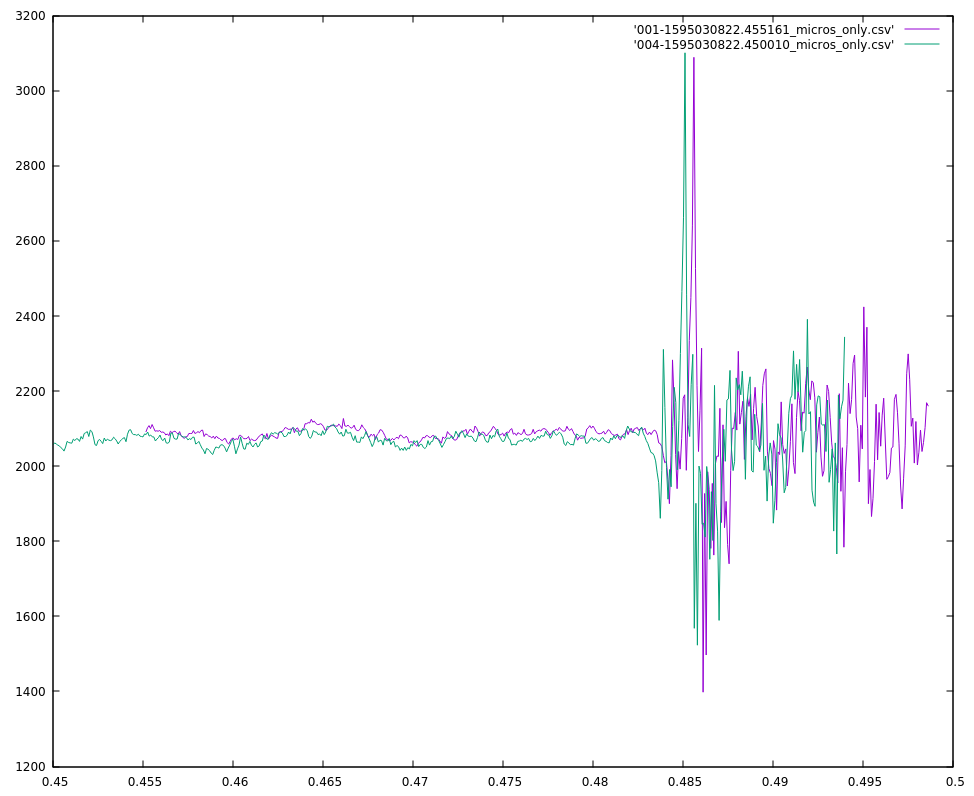
The server receives these sound buffers from an individual microphone controller. The server groups these buffers together based on time. Each buffer spans about 22 milliseconds, and buffers from the same controller that arrive within 50 ms of each other are considered to be part of the same sound (50 ms chosen so that 1 or 2 dropped buffers don’t break up a single sound.)
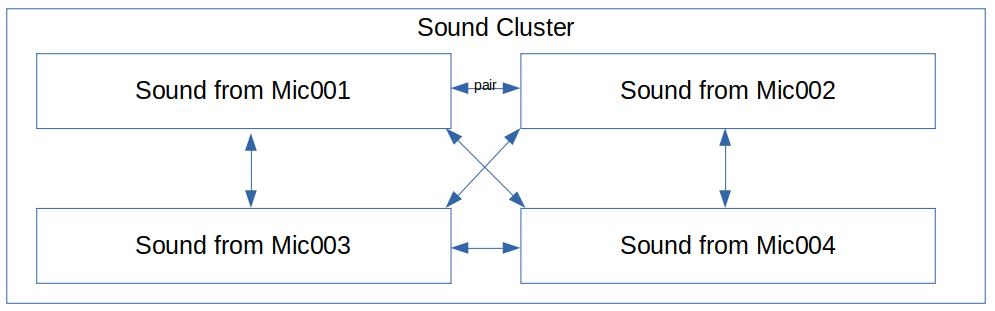
Sounds from different microphone controllers are grouped together by the server into sound clusters that occur within some small time frame that will be bounded by the time it takes for sound to travel between microphones (plus some small amount to allow for timing errors.) If the sound cluster contains sounds from more than 2 microphones, it will be considered to have originated from the same event.
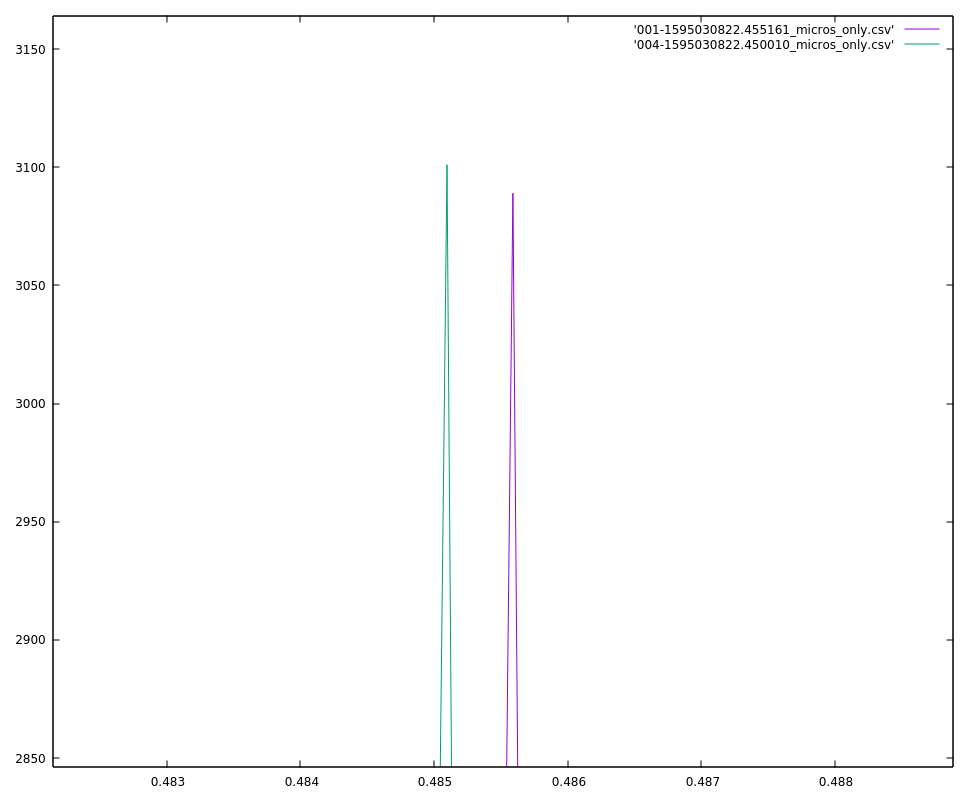
The server then tries to determine where the event happened. It does this by calculating the time-offsets and similarities of each pair of sounds in a cluster. If the similarity of a pair of sounds falls below some threshold then the time-offset for that pair will be discarded. The remaining time-offsets for a cluster will then be combined the the physical arrangement of their corresponding microphone assemblies and used to calculate a best-guess for the location of the event.