So, this project has been a put on a shelf for a while, but what’s happened in 4 years?
Several things–most notably we’ve moved out further into the suburbs, and the loud sounds seem to have mostly abated. Whereas at the old place, I was pretty much guaranteed a loud sound every few days, but here I’m limited to a few clusters of booms around the 4th of July and New Year’s Eve, with very little else in the way of sample data. I don’t think my new neighbors would appreciate my setting off fireworks just to have sample data. I like to tell myself that the sounds at the old place were fireworks, but the reality was more likely a mixture of gunshots and fireworks.
Second, I’ve just lost steam on this. The problems with getting the timing right and other things like that have convinced me that maybe I need to re-think the microphone design. I’m thinking of using a dedicated GPS module on each microphone unit to establish both location and time more accurately, but that pushes up the cost considerably. GNSS/GPS receivers can be had for $30 or $35 dollars on convenient breakout boards, but that nearly doubles the cost per microphone. At that point maybe I should consider using a Raspberry Pi Zero 2W or similar, though the lack of analog inputs is problematic.
I haven’t had much time to work on this for the last month or so because work got a little crazy. Now that the Big Project is over, I’ve started back into this.
My first attempt at the triangulation is more complex than I initially expected. First I take each sound pair, and using the skew and the locations of the microphone, calculate a pair of bearings originating from the midpoint between those two microphones. Then I take those midpoints and bearings to calculate intersections, and I get four intersections for each pair of midpoints, and there can be up to 6 midpoints, therefore 15 midpoint pairs, and 60 locations. However, I ignore midpoint pairs that are too close together (2 meters or less), and also discard any location more than a couple of kilometers away as being a false signal, but that still leaves between 5 and 25 locations.
Next I try to cluster the locations by finding locations that are within 100m of each other. This isn’t working quite as well as I had hoped, but that is likely due to poor data quality. I’ve just got got the microphones scattered around my office, rather than at the corners of my property, but the algorithm is assuming the mics are at their final location. Because of the relatively low skew times, the calculations are all coming out as if the sounds originate in the center of my house.
I’ve got to work on the enclosures so I can get the microphones to their proper locations. Unfortunately the fireworks that were pretty common near the 4th of July have abated, so I will have relatively few data points to work with.
I’ve got the server end of the solution a little farther along. It now recognizes multiple buffers as belonging to the same sound, can group those sounds into likely pairs for comparison, automatically determine their time skews (offsets) and associate them with an event.
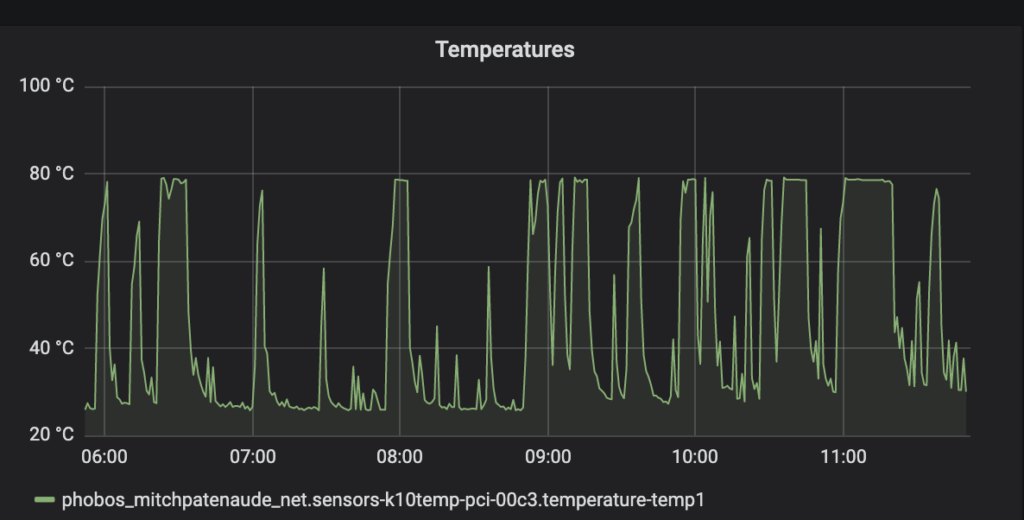
There are still problems getting the microcontrollers to agree on what time it is, and now the server is problematic as well. As I mentioned previously, the algorithm that I use to determine the time offsets is CPU intensive, and now that it’s being done automatically the server is under much heavier load. It’s got 8 cores, so dedicating 4-6 of them to running parallel computations shouldn’t be an issue. Apparently however, the heat-sink on the CPU isn’t as effective as it could be, so first the CPU frequency scales up to handle the load, which causes the temperature to shoot up to nearly 80℃ (see below) which causes the CPU to scale back it’s frequency to deal with the heat. I suspect that all that scaling up and down is playing havoc with it’s internal timekeeping, because it suddenly loses track of the time by 500ms or more, causing it to inappropriately break up new sounds into multiple buffers as the time jumps back and forth. It’s also messing up the microphone microcontrollers, which suddenly get large offsets from the server, quickly followed by large offsets in the opposite direction as the server time corrects itself.
It’s getting hot in here
So I’m going to take two steps to combat this. First I’m going to take the heatsink off the CPU and see if I can get it to be more effective by cleaning the surfaces and applying a thin coat of new thermal compound. Second, I’m going to move the role of NTP server to a new box that doesn’t have as much of an issue with spiky cpu load. (And if that isn’t stable enough, I may dedicate a Raspberry Pi act as a NTP server.)
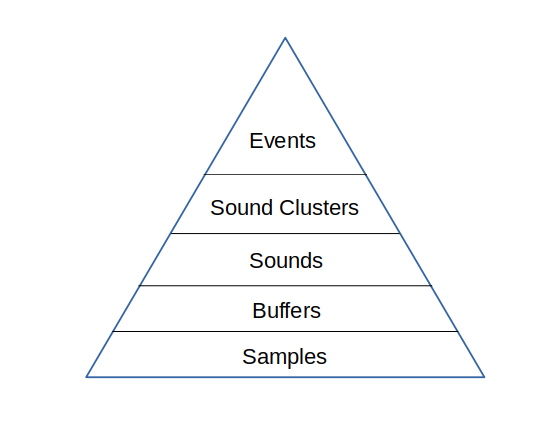
I’m starting to tackle the problem of identifying the individual sounds and correlating them with things detected by all the microphones. In order to do this I’m going to come up with abstractions for the data at each stage in the process. I’m going to start designing this from the bottom up. The terms for each abstraction are presented in bold the first time it is used.
The hierarchy of abstractions
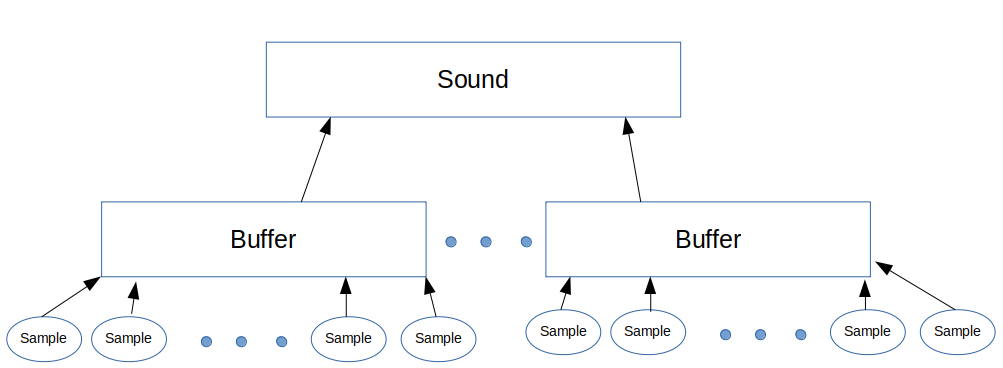
At the base of the pyramid of abstractions are samples. These are individual measurements of the voltage the microphone element produces. The samples are grouped together into buffers. Currently the size of a buffer is 512 samples, collected at approximately 20kHz. The microcontroller decides if the buffer is interesting by looking for samples where the voltage falls above a threshold. If interesting, it then forwards that buffer and preceding and following buffers to the server.
The server receives these sound buffers from an individual microphone controller. The server groups these buffers together based on time. Each buffer spans about 22 milliseconds, and buffers from the same controller that arrive within 50 ms of each other are considered to be part of the same sound (50 ms chosen so that 1 or 2 dropped buffers don’t break up a single sound.)
Sounds from different microphone controllers are grouped together by the server into sound clusters that occur within some small time frame that will be bounded by the time it takes for sound to travel between microphones (plus some small amount to allow for timing errors.) If the sound cluster contains sounds from more than 2 microphones, it will be considered to have originated from the same event.
The server then tries to determine where the event happened. It does this by calculating the time-offsets and similarities of each pair of sounds in a cluster. If the similarity of a pair of sounds falls below some threshold then the time-offset for that pair will be discarded. The remaining time-offsets for a cluster will then be combined the the physical arrangement of their corresponding microphone assemblies and used to calculate a best-guess for the location of the event.
Maybe I was too hasty in thinking that my curve matching algorithm wasn’t going to be useful. I had a few loud booms go off tonight with 4 mics scattered around the office and the windows open. Mics 1 and 4 were by the open window, and mics 2 and 3 were by my computer about 6 ft. (1.8 m) away. All 4 detected at least one of the big echoing booms. My algorithm gave reasonable offsets and reasonable waveform matches once skewed.
Mic 2 skewed back by 5.06 ms.
All 4 skews were in the 5 to 7 ms range, which is right about what I’d expect for microphones that were 6ft. apart on the direction of travel (6ft/1127fps = 0.005324 seconds, or 5.3 ms). Now to be fair, this was pretty much a best-case scenario for my algorithm. These were long, low rumbling booms rather than simply a loud crack. Still.. Mics 1 and 4 heard the crack at the beginning and mics 2 and 3 didn’t, and it didn’t throw off the algorithm.
After writing up my (computationally intensive) code to measure the skew between the signals from two microphones, I’ve made a discovery. It works great for stuff with complex, low-frequency sounds like my chair creaking, but not so well in other cases. For sustained, constant frequency sounds (like beeps) it gets confused about which of several possible alignments are “best”. Take for example this short beep as heard by two adjacent microphones:
My visual best fit says the green waveform needs to be shifted a few hundred microseconds to the right, and that these were almost in alignment already. However, my algorithm shifted it ~13,000 microseconds to the left.
It did make the wave peaks line up, but since this is a more or less steady tone, that happens every couple of milliseconds. I’m also sure it maximized my fit function, but to my eye the overall envelopes don’t match nearly as well. I think there are two factors working against my algorithm here. First, the waveforms weren’t complete–the beginning of the waveforms was cut off by different amounts in the different samples. I’ve taken measures to reduce the likelihood of that happening, but I can’t eliminate it altogether. Second, this was a fairly steady tone–as I already mentioned, and there were lots of “pretty good” fits that it had to choose from.
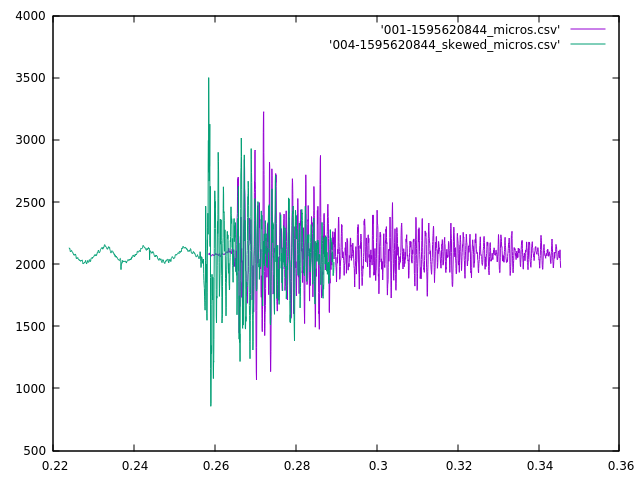
The other situation that it doesn’t handle well is more problematic. It appears that for short, sharp sounds–like a clap, whip crack, fireworks or gunshots–there is too much high-frequency information that the two mics will sample differently, and since my sampling rate is about 20kHz, I really can only differentiate frequencies below about 10kHz (5kHz for a good fit). See the Nyquist-Shannon theorem for a more complete discussion as to why. So, when I have a signal with a lot of high-frequency information, I can’t really match it effectively. Take this example of a clap when the mics where a few feet apart (1-2 meters):
The apparent shift shouldn’t need to be large, but the algorithm doesn’t pay attention to that, and it came up with a fit that looked like:
This is a much worse fit according to my eye. I think a better technique in this case it to line up the beginning of the loud sounds, but I need to come up with a way to identify those algorithmically. I’ll probably use some heuristic like looking at the time of the first samples to fall significantly further from the mean than I’d been seeing previously, but that requires that I have a nice quiet section before the sound happens. I’ve taken steps to try to make sure that I have that (by sending the prior buffer as well when I detect an anomaly), but it doesn’t always work out as you can see in the purple curve.
One of the technical challenges in this project is to figure out the exact time offset of two waveforms. I think I’ve solved that sufficiently.
The Good
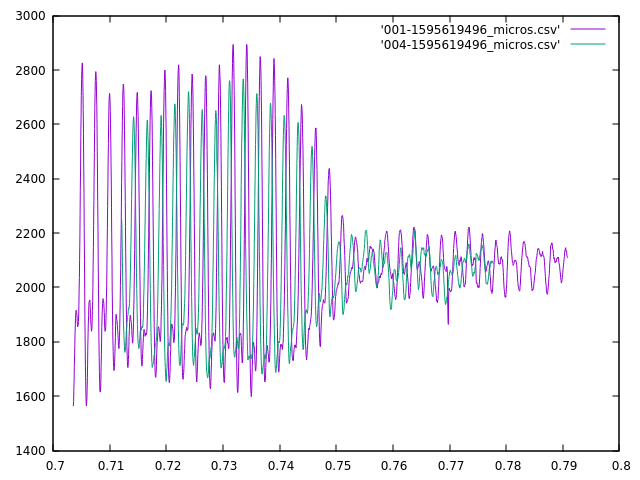
My algorithm correctly detects the time skew of two waveforms. Here’s the raw data from two mics:
Without correction, the two waveforms look disjoint
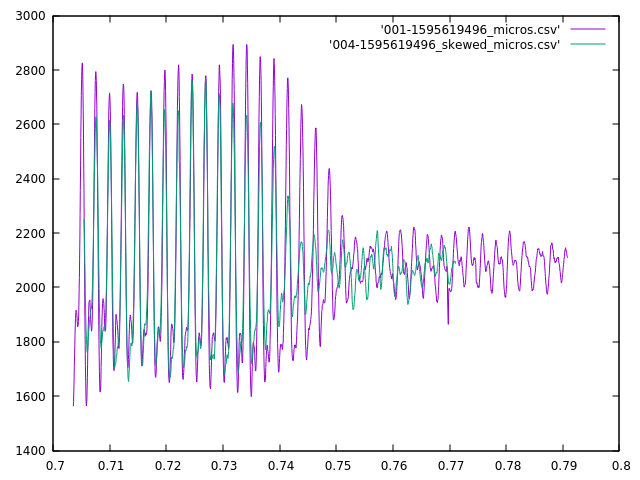
And here’s after the skew is corrected for:
With the curve from Mic 004 skewed forward by 2.44 milliseconds
The two waveforms are a very good match.
The Bad
The algorithm is very computationally intensive. My first pass at the code, finding the skew took 10-20 minutes for two 50 millisecond waveforms. With a little optimization from caching interpolation results and discarding excess precision, I got it down to 1-2 minutes (much better, but still pretty slow. I may be able to get another factor of 2 or 3 my switching to C++ from Python, but getting the code right will be more difficult.
The Skewed
It has occasionally detected skews in the range I’d expect for two microphones next to each other (a few hundred microseconds), but most of the skews have been in the 2-2.5 millisecond range, which is about 10 times what I’m hoping for. More work on time sync is needed apparently.
The downside to increasing the sample rate is that I also increased the timing error that accumulates during a sampling buffer. Look at these sequential data buffers:
I’ve got a gap
There’s a gap of more than 400 microseconds between the last measurement of the first packet and the first measuement of the second. That gap isn’t real though. There’s actually about a 42-43 microsecond gap in real time, but because I send the measurement interval as a whole number of microseconds between messages, there’s a fraction of a microsecond that gets lost to truncation. In this case, the actual interval of 42.72 microseconds gets truncated to 42 microseconds when sent to the server, and that means that there’s about a 370 microsecond error by the end of the packet (0.72 microseconds * 512 measurements in the packet).
Currently the measurement packet has a 22 bytes of header, including both the timestamp of the beginning of the packet (8 bytes) and the number of microseconds between measurements (2 bytes). I could redesign the measurement packet so that the same two bytes pass 100ths of microseconds rather than whole microseconds, and that would allow up to 655.35 microseconds as a measurement interval without changing the overhead of the packet. (I’ve only got about 1450 bytes to work with in a UDP packet that’s going to travel over WiFi and Ethernet, so I’m trying to be frugal with headers and leave as much space as possible for actual measurements.)
I have been assuming that approximately 10kHz was about the maximum sampling rate I could achieve, but it turns out I was very wrong. So far I’ve gotten up to approximately 20kHz and am not seeing any degradation in performance. I’m not sure how high I can (or should) crank this up for optimal system performance, but I’ve already increased the precision from 1 reading every 85 microseconds to 1 every 42 microseconds. Now if only my clock were that accurate.
I’ve been noticing that the microphone that has the DHT-11 temperature sensor consistently under-performs the other microphone in terms of how well is stays in sync with the NTP server. I have documented previously that trying to read a non-existent sensor caused major sync issues, but I now know that even if the sensor is working properly, it still throws the sync off slightly.
On mic 001 (the one with the temperature sensor). I was seeing the average offset being somewhere around +/-1300 microseconds, whereas on mic 004 (the one without the sensor or code to read it). I was typically seeing offsets of +/-300-400 microseconds (1/4 to 1/3 as large). So I disabled the DHT-11 on mic 001, and within 15 minutes the average offset was +/- 400-500 microseconds, and the timing of received sound waves was much more in sync.
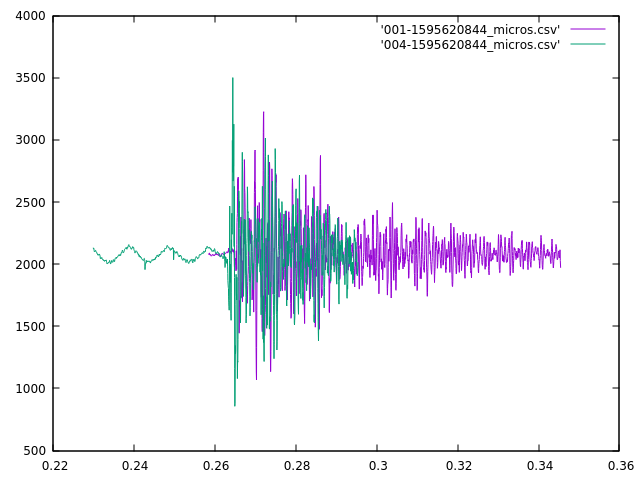
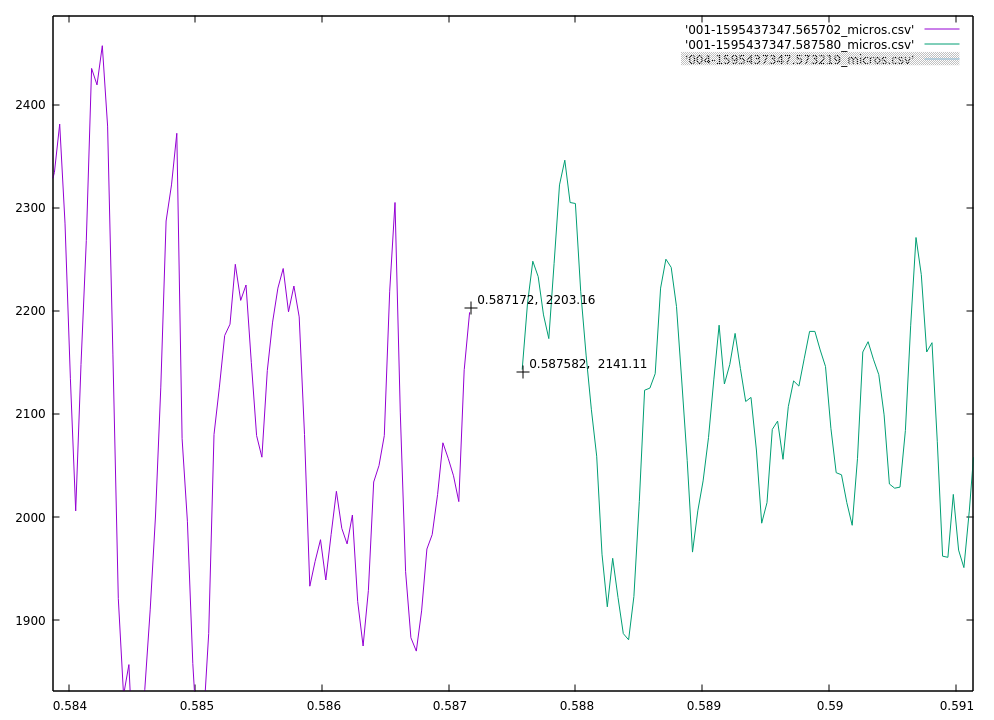
I have no idea what this was, but both mics agree when it was.
And zooming in on that first big positive peak you can see that they’re only about 400 microseconds apart, which is pretty good.
.9093730-.909344 = .000386 seconds, or 386 microseconds difference
It’s not the 100 to 200 microsecond offset I’m looking for, but I can live with this level of error.
Now what am I going to do with the temperature sensor? I still need to be able to measure ambient air temperature to calculate the speed of sound accurately, but it was never a requirement that I have 4 of them or that they be co-located with microphones. I have some spare ESP8266 feathers now, and while they’re not good for the microphones, I can easily re-purpose them to being a couple of temperature sensors. I’ll play with low-power deep-sleep and have them wake up every 30 seconds or so to check the temp and report in. That should give me a fairly accurate and current air temp.